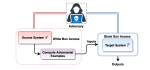
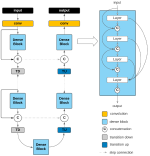
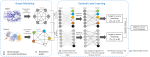
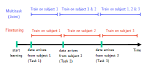
Computational Autonomy
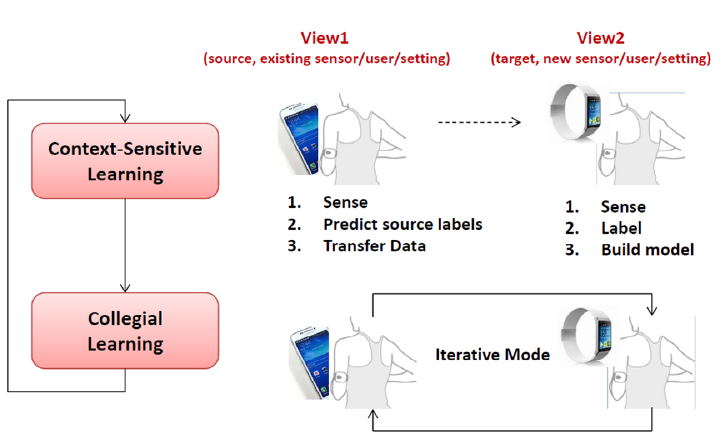
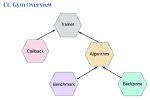
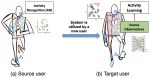
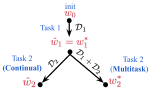
We envision that wearables of the future must be computationally autonomous in the sense that their underlying computational algorithms reconfigure automatically without need for collecting any new labeled training data. In this project, we investigate development of multi-view learning algorithms that enable the vision of computationally autonomous wearables and result in highly sustainable and scalable wearables of the future. The algorithms and tools are validated through both in-lab experiments and using data collected in uncontrolled environments.
Embedded Machine Intelligence Lab
Research Lab
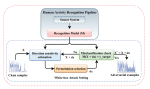
The current focus of our research in the Embedded Machine Intelligence Lab (EMIL) is on design, development, and validation of algorithms, tools, and technologies that enhance utilization and large-scale adoption of digital health systems. To validate and refine the new technology, we actively collaborative with domain experts, community stakeholders, and end-users. This end-to-end approach results in innovative, evidence-based and cost-conscious health solutions for individuals and care providers.
Publications