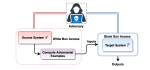
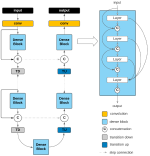
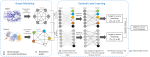
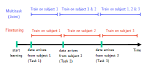
Computational Autonomy
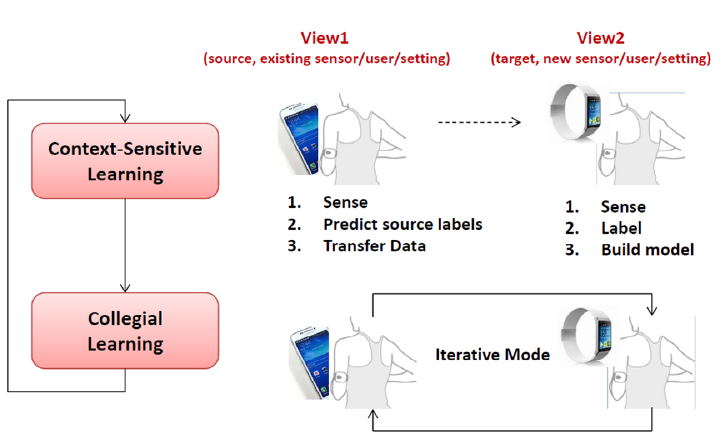
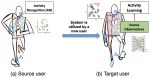
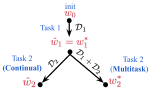
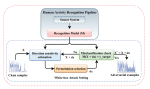
We envision that wearables of the future must be computationally autonomous in the sense that their underlying computational algorithms reconfigure automatically without need for collecting any new labeled training data. In this project, we investigate development of multi-view learning algorithms that enable the vision of computationally autonomous wearables and result in highly sustainable and scalable wearables of the future. The algorithms and tools are validated through both in-lab experiments and using data collected in uncontrolled environments.
Embedded Machine Intelligence Lab
Research Lab
At the Embedded Machine Intelligence Lab (EMIL) at Arizona State University, we develop next-generation AI, sensing, and digital health technologies that bridge the gap between algorithmic innovation and real-world clinical impact. Our research focuses on the design, development, and validation of robust, interactive, efficient, and trustworthy machine learning methods for real-world pervasive systems operating under dynamic and resource-constrained conditions.
Publications