Loss landscapes and optimization in over-parameterized non-linear systems and neural networks
Abstract
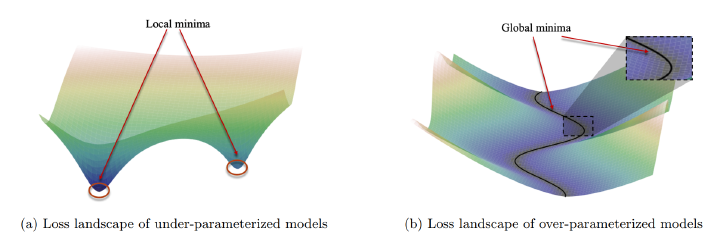
The success of deep learning is due, to a large extent, to the remarkable effectiveness of gradientbased optimization methods applied to large neural networks. The purpose of this work is to propose a modern view and a general mathematical framework for loss landscapes and efficient optimization in over-parameterized machine learning models and systems of non-linear equations, a setting that includes over-parameterized deep neural networks. Our starting observation is that optimization problems corresponding to such systems are generally not convex, even locally. We argue that instead they satisfy PL∗, a variant of the Polyak- Lojasiewicz condition on most (but not all) of the parameter space, which guarantees both the existence of solutions and efficient optimization by (stochastic) gradient descent (SGD/GD). The PL∗ condition of these systems is closely related to the condition number of the tangent kernel associated to a non-linear system showing how a PL∗-based non-linear theory parallels classical analyses of over-parameterized linear equations. We show that wide neural networks satisfy the PL∗ condition, which explains the (S)GD convergence to a global minimum. Finally we propose a relaxation of the PL∗ condition applicable to almost over-parameterized systems.
Reza Rahimi Azghan
Grad Research Associate
I am a Ph.D. student at Arizona State University. I work as a Graduate Research Associate at Embedded Machine Intelligence Lab (EMIL) under the supervision of Dr. Hassan Ghasemzadeh.