Abstract
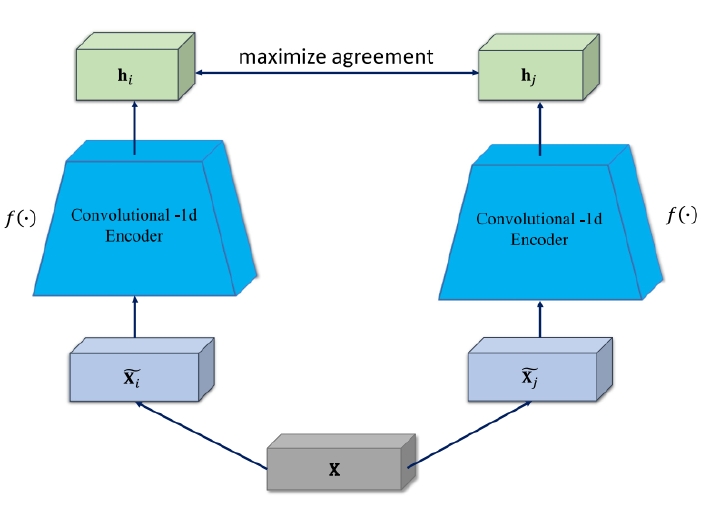
Deep learning architectures usually require large scale labeled datasets for achieving good performance on general classification tasks including computer vision and natural language processing. Recent techniques of self-supervised learning have opened up new a research frontier where deep learning architectures can learn general features from unlabeled data. The task of self-supervised learning is usually accomplished with some sort of data augmentation through which the deep neural networks can extract relevant information. This paper presents a novel approach for self-supervised learning based time-series analysis based on the SimCLR contrastive learning. We present novel data augmentation techniques, focusing especially on time-series data, and study their effect on the prediction task. We provide comparison with several fault classification approaches on benchmark Tennessee Eastman dataset and report an improvement to 81.43% in the final accuracy using our contrastive learning approach. Furthermore we report a new benchmark of 80.80%, 81.05% and 81.43% for self-supervised training on Tennesee Eastman where a classifier is only trained with 5%, 10% or 50% percent of the available training data. Hence, we can conclude that the contrastive approach is very successful in time-series problems also, and further suitable for usage with partially labeled time-series datasets.
Reza Rahimi Azghan
Grad Research Associate
I am a Ph.D. student at Arizona State University. I work as a Graduate Research Associate at Embedded Machine Intelligence Lab (EMIL) under the supervision of Dr. Hassan Ghasemzadeh.