Abstract
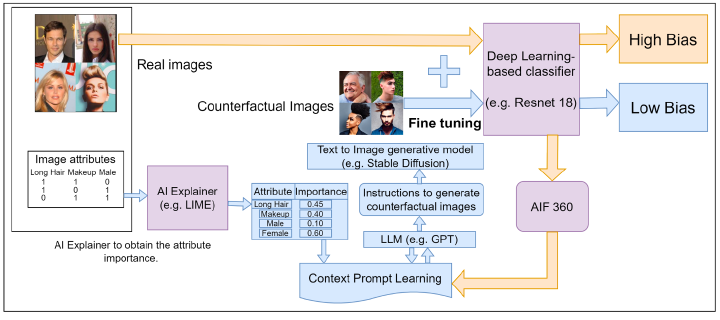
With the widespread adoption of Deep Learning-based models in practical applications, concerns about their fairness have become increasingly prominent. Existing research indicates that both the model itself and the datasets on which they are trained can contribute to unfair decisions. In this paper, we address the data-related aspect of the problem, aiming to enhance the data to guide the model towards greater trustworthiness. Due to their uncontrolled curation and limited understanding of fairness drivers, real-world datasets pose challenges in eliminating unfairness. Recent findings highlight the potential of Foundation Models in generating substantial datasets. We leverage these foundation models in conjunction with state-of-the-art explainability and fairness platforms to generate counterfactual examples. These examples are used to augment the existing dataset, resulting in a more fair learning model. Our experiments were conducted on the CelebA and UTKface datasets, where we assessed the quality of generated counterfactual data using various bias-related metrics. We observed improvements in bias mitigation across several protected attributes in the fine-tuned model when utilizing counterfactual data.
Asiful Arefeen
Graduate Research Assistant
I am a PhD student at Arizona State University (ASU). I am working under the supervision of Professor Hassan Ghasemzadeh at the Embedded Machine Intelligence Lab (EMIL). I am interested in explainable AI, using AI to generate interventions in digital health, machine learning, passive sensing and mobile health. I received a BS in Electrical & Electronic Engineering from Bangladesh University of Engineering & Technology (BUET) in 2019 and an MS in Biomedical Informatics from Arizona State University in 2023.