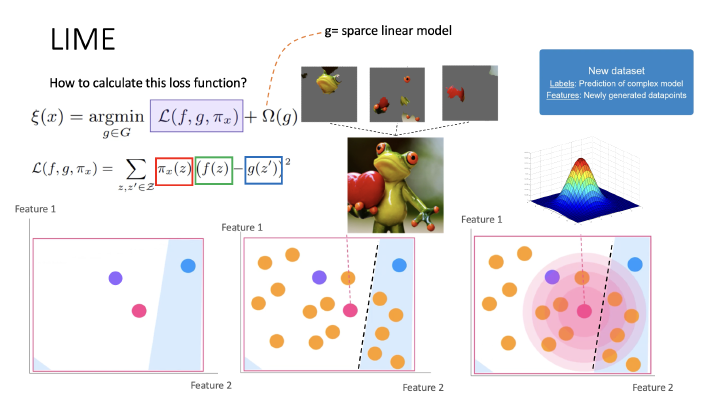
Abstract
Despite widespread adoption, machine learning models remain mostly black boxes. Understanding the reasons behind predictions is, however, quite important in assessing trust, which is fundamental if one plans to take action based on a prediction, or when choosing whether to deploy a new model. Such understanding also provides insights into the model, which can be used to transform an untrustworthy model or prediction into a trustworthy one. In this work, we propose LIME, a novel explanation technique that explains the predictions of any classifier in an interpretable and faithful manner, by learning an interpretable model locally around the prediction. We also propose a method to explain models by presenting representative individual predictions and their explanations in a non-redundant way, framing the task as a submodular optimization problem. We demonstrate the flexibility of these methods by explaining different models for text (e.g. random forests) and image classification (e.g. neural networks). We show the utility of explanations via novel experiments, both simulated and with human subjects, on various scenarios that require trust, deciding if one should trust a prediction, choosing between models, improving an untrustworthy classifier, and identifying why a classifier should not be trusted.
Asiful Arefeen
Graduate Research Assistant
I am a PhD student at Arizona State University (ASU). I am working under the supervision of Professor Hassan Ghasemzadeh at the Embedded Machine Intelligence Lab (EMIL). I am interested in explainable AI, using AI to generate interventions in digital health, machine learning, passive sensing and mobile health. I received a BS in Electrical & Electronic Engineering from Bangladesh University of Engineering & Technology (BUET) in 2019 and an MS in Biomedical Informatics from Arizona State University in 2023.