Abstract
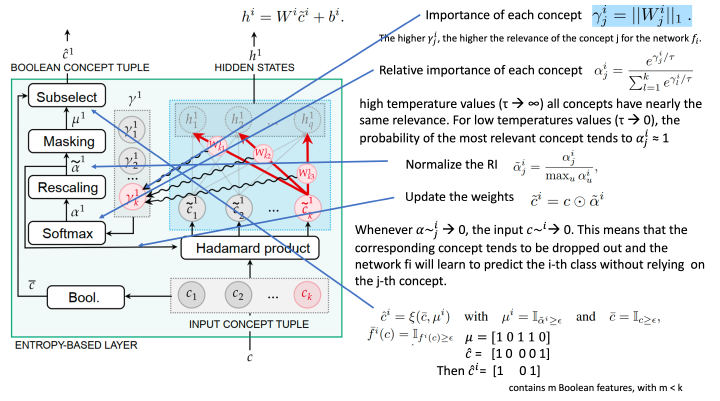
Explainable artificial intelligence has rapidly emerged since lawmakers have started requiring interpretable models for safety-critical domains. Concept-based neural networks have arisen as explainable-by-design methods as they leverage human-understandable symbols (i.e. concepts) to predict class memberships. However, most of these approaches focus on the identification of the most relevant concepts but do not provide concise, formal explanations of how such concepts are leveraged by the classifier to make predictions. In this paper, we propose a novel end-to-end differentiable approach enabling the extraction of logic explanations from neural networks using the formalism of First-Order Logic. The method relies on an entropy-based criterion which automatically identifies the most relevant concepts. We consider four different case studies to demonstrate that (i) this entropy-based criterion enables the distillation of concise logic explanations in safety-critical domains from clinical data to computer vision; (ii) the proposed approach outperforms state-of-the-art white-box models in terms of classification accuracy and matches black box performances..
Asiful Arefeen
Graduate Research Assistant
I am a PhD student at Arizona State University (ASU). I am working under the supervision of Professor Hassan Ghasemzadeh at the Embedded Machine Intelligence Lab (EMIL). I am interested in explainable AI, using AI to generate interventions in digital health, machine learning, passive sensing and mobile health. I received a BS in Electrical & Electronic Engineering from Bangladesh University of Engineering & Technology (BUET) in 2019 and an MS in Biomedical Informatics from Arizona State University in 2023.