Abstract
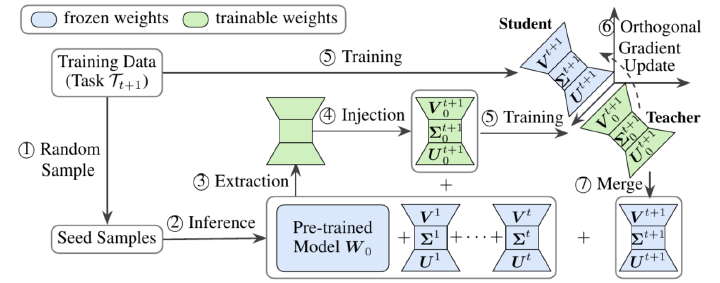
Large Language Models (LLMs) have demonstrated profound capabilities due to their extensive pre-training on diverse corpora. However, LLMs often struggle with catastrophic forgetting when engaged in sequential task learning. In this paper, we propose a novel parameter-efficient approach for continual learning in LLMs, which empirically investigates knowledge transfer from previously learned tasks to new tasks through low-rank matrix parameters, enhancing the learning of new tasks without significant interference. Our method employs sensitivity-based analysis of low-rank matrix parameters to identify knowledge-specific parameters between sequential tasks, which are used to initialize the low-rank matrix parameters in new tasks. To maintain orthogonality and minimize forgetting, we further involve the gradient projection technique that keeps the low-rank subspaces of each new task orthogonal to those of previous tasks. Our experimental results on continual learning benchmarks validate the efficacy of our proposed method, which outperforms existing state-of-the-art methods in reducing forgetting, enhancing task performance, and preserving the model’s ability to generalize to unseen tasks.
Reza Rahimi Azghan
Grad Research Associate
I am a Ph.D. student at Arizona State University. I work as a Graduate Research Associate at Embedded Machine Intelligence Lab (EMIL) under the supervision of Dr. Hassan Ghasemzadeh.